Why ECA?
BSG has already some functions to analyze: Analyse on the fly and Analyse a game. Usually, they are used to analyze games with multi moves. For each position (created by making a move) BSG runs one (or several) engines to compute and give ideas/opinions about that position. Typically the engine gives only a PV (including the best move) and a score (some engines may have extra values of Win/Draw/Loss) for a position. That information is good enough for many tasks and purposes.
However, the problem occurs when the user wants some more and/or deeper information about a given position. The above analysis results can’t answer some questions, such as how good the 2nd, 3rd… best lines, what the reasons the engine picks this line as the PV but not other lines. He may want to dig deeper on several variants, find out how good, bad, blunder, trapped on them. Sometimes by knowledge and experience, he may know the current PV is really bad, trapped but because of being blunder, the analyzing chess engine may need a huge more amount of time to get out. However, it gets hard to tell the engine to stop that PV and try other variants since traditional analysis functions make it hard for users to interfere.
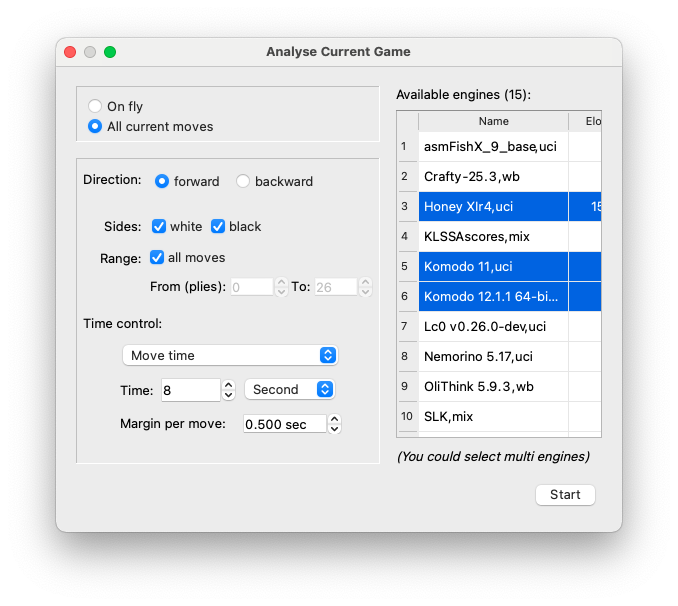
Fig. 1 “Traditional” analysis functions: analysis on fly and analysis whole game, using one or multi-engines
What is ECA?
It is a new analysis function. “Extreme Chess Analysis” (ECA) can help users to analyze deeply chess positions and collect much more information for variants. Instead of having only one best line, it calls engines to compute several selected (or all) variants. Instead of keeping only a PV and discard all other lines, it keeps them all with their information (scores, Win/Draw/Loss as well as some others) to refer to later. Users can easily track lines to find good, bad, blunder moves, answer many new questions. It starts with a given position but can extend and cover a large number of positions, variants that users are interested in.
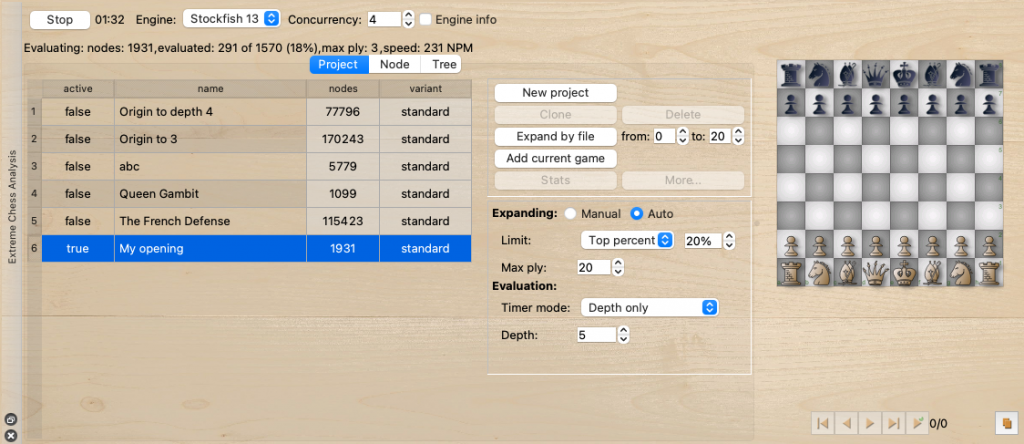
Fig. 2 Extreme Chess Analysis Dock Panel
Tree
ECA starts with a given position (start position), selected by the user. From that node, it expands to children’s positions by making moves. Those children can be expanded again many times. ECA uses some engines to evaluate leaf positions and then backpropagate those scores to their parents and continue to ancestor nodes.
All nodes and information can be kept in an alike-tree structure. Each node of the tree presents a position. The connection line between two nodes is a move (it is a one-way direction, from node A we can visit node B by making move M but we can’t visit back from B to A by using that move). The root of the tree is the start position.
Compact the size
If there are no limitations the tree can be expanded fully. In that case, the tree somewhat looks similar to ones we imagine about a full opening tree or ones when calculating Perft. The problem is that the tree may grow exponentially by depth. For example, at depth 6 the Perft tree of the origin chess position has over 112 million nodes. If each node takes only 1 second to evaluate, that tree requires 3.5 years to complete computing. Thus ECA tries to reduce the tree size as much as possible by eliminating any redundant nodes: a chess position should be represented by only one unique node. The total of nodes is reduced significantly. Now at depth 6, the tree has near 900 thousand nodes, 12 times smaller (it needs about 3 months to complete with 1 second for each node).
Keeping a smaller size is the key to the “survival” factor of this feature since it may require calculating too much.
Because of using unique nodes, some nodes may have multi parents. By definition, the data structure becomes not a real tree but a directed graph. However, we still call it a “tree” since many users got familiar with that term and it’s easier to imagine and work with. We present our data as a standard tree too.
What users can do with a tree
Users can interact with the tree to:
- View the tree: see all information about a given node: the move list from the start position to that node, the associated chessboard, the evaluation (by engine for that node), scores (back propagated), the children…
- Set flag “ignored”: tell ECA to ignore some nodes from evaluating and expanding
- Manual expand nodes
- Expand the tree by feeding games or databases (PGN files or BanksiaGUI databases .bgdb) or Polyglot opening books
View the tree
The tree can be viewed in two forms: a tree view and a node view. Those views are on appropriate tabs.
- Tree view: gives a wider, panoramic view of the tree. It is easy to find information about siblings, ancestors, grandchildren, compare variants. However, it shows fewer details. When the user goes deeper on the tree, it may expand on the screen, take huge space, show too many nodes and information makes it harder to read, find and navigate. At the moment users can’t set flag “ignored” for nodes using that view nor expand manually.
- Node view: at one time only information of a node with their children is displayed. With a glance, users cannot get information of farther nodes such as its parents, siblings, grandkids… That’s hard to compare between variants… Instead, it displayed more information such as evaluation info and allow users to set on/off ignored flags (to stop auto-expanding) and expand manually.
Users can use any form, depending on tastes and/or tasks/purposes.
Both views can be navigated by both mouse and keyboard (using the arrow, home, page keys, W, A, S, D) for quick navigation.
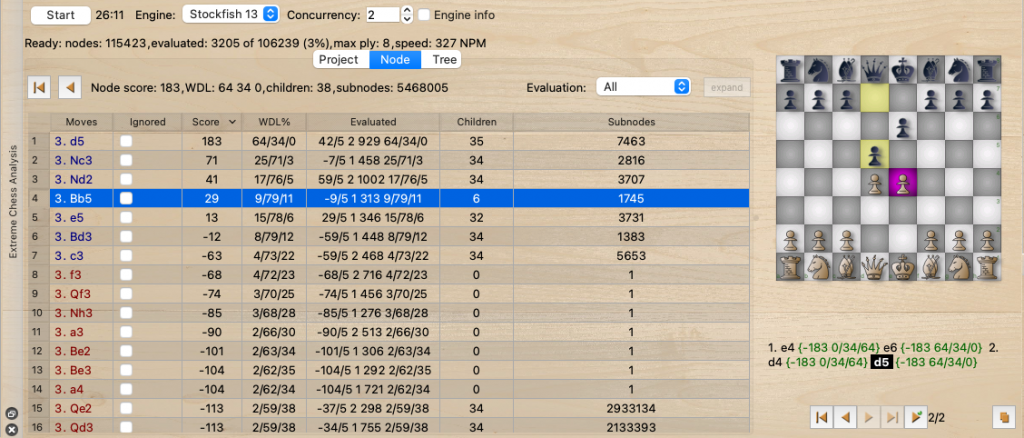
Fig. 3 Node view
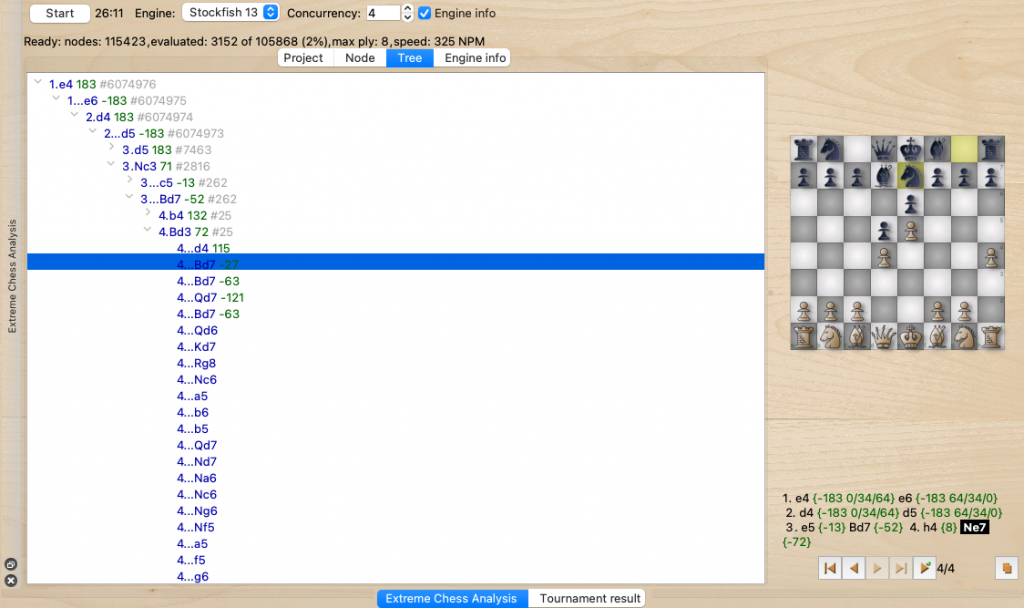
Fig. 4 Tree view
How the tree created?
ECA works in two consequent phases:
- Evaluation: all leaf nodes without score will be evaluated (and maximum one only for each node) by an engine. Whenever a node evaluated, its score will be propagated up to the tree (towards to the root), using minimax rule. If there is any change, involving children of nodes will be re-sorted by their scores
- Expanding (auto expanding mode only): it starts when all leaf nodes are evaluated. All leaf nodes will be checked if they are in the good range and then expanded to one level
Within phase 1 (evaluation) scores may be set and backward many times and affect a large number of nodes. Some nodes may stop expanding early but then their scores change from “bad” to “good” (and vice versa) and are expanded after a while.
When ECA is useless?
- To analyse whole games with multi moves
- The user needs only the best line for each given position
- All traditional analysis functions (Analysis on Fly and Analysis whole game) are enough for the user
- The user doesn’t want long time computing
- The user doesn’t bother to look into a headache, complicated structure such as ECA’s trees
Some notes, tips
- “Evaluated”: is the computing results came directly from the engine. In full form they are displayed in “semi-standard”: score/depth time nodes W/D/L. Inner nodes may be not evaluated thus not every node has that values. Depth and time show how quality of the computing. Node shows how hard of that computing
- “Score”: are values created by back-propagation
- WDL: those values are back-propagated as scores. However, those values are not used to select by minimax rule
- Ignored: flags the node that it will be ignored completely as it is not existent when evaluating and expanding
- Nodes in red colours: Low scores nodes, out of expanding range. They are still evaluated but won’t be expanded for the next round
- Accuracy: The total of nodes is accurate. However, other numbers such as sub-nodes, back-propagated scores… may not be accurate, consistent sometimes since they may be affected by chess loops/repetitions
- If users don’t expand fully (all moves) for a given moves, all missing moves won’t be counted when evaluating and expanding (similar to ignored-ones)
- Engines: when computing for ECA they use general setups/options (set via Settings dialog)
- Engine info and log: Those engines don’t save any info to log files (to avoid being messy and write too much). If users need to monitor them, click on the check box “Engine info” on ECA panel. It will add a new tab to show engines’ info
- Stop: If engines are computing and the user wants to quit BSG, it is better to stop those engines first (by clicking on the button “Stop”) and give BSG a few seconds thus BSG can write down all computing data. The user can reduce the number of concurrency to zero to make engines quit gently
- Backup: Frequently backup data (by copying files) and/or clone projects are good way to save your precious data
- Size: Keep an eye to the number of nodes. Users are strongly suggested to monitor and keep the tree size as small as possible
- Reset scores: At the beginning the user may make engines do fast search (using low depth, time) thus BSG can grow the tree quickly to the depth/size he wants. Thus he may quickly have some things to study, a better view about the variants, understanding about the engine. With that knowledge, he can set ignored flags to some nodes, expand manually some other branches. After all, he may increase the qualifications of analysing to use longer by reseting all scores to recalculate. By doing that BSG can save time from internal, bad nodes